סריקת אתרי חנויות יכולה להיות מאוד מאוד מתסכלת. גם אם האתר בנוי כמו שצריך מבחינת קוד והיררכיה – מספיק שיש כמה אפשרויות חיתוך לקטגוריות שהסריקה תגיע לאלפי עמודים עבור 5-6 קטגוריות (תארו לכם שאפשר בכל קטגוריה לפלטר 4-5 פרמטרים, תחשבו כמה וריאציות אפשריות אפשר להגיע – יגמרו לכם האצבעות מהר מאוד. השיא שלי היה שהפסקתי סריקה של חנות ב1.4 מליון רשומות – באתר עם 10 קטגוריות בלבד…).
מכיוון שלרוב אנחנו ממש לא צריכים סריקה של כל החיתוכים והפלטורים האפשריים – כדאי להגדיר את הצפרדע כך שתסרוק אך ורק את העמודים הראשיים, הקטגוריות, המוצרים וזהו.
שימו לב לכמות התוצאות שיצאו לי בסריקה רגילה בלי שום הגדרות:

אז איך מייעלים את כל העסק?
סינון עמודים קנונים
קודם כל – מחליטים שאנחנו לא נותנים לצפרדע לסרוק עמודים קנונים.
למה?
פשוט מאוד – עמוד קנוני באתר חנות בד"כ זה עמוד קטגוריה מפולטר. כלומר – אותו עמוד קטגוריה ראשי (למשל: חולצות) רק שמציג תוצאות שמכילות פרמטרים מסוימים (למשל: מידות 34,36 ממותג "נייק"). ולכן אין שום סיבה שהצפרדע תסרוק אותו – הרי היא לא תגלה מוצרים חדשים בחנות בעמוד קטגוריה מצומצם…
צמצום עמודי Rel=prev/next
החלק הזה יעבוד – רק כשהחנות בנויה כמו שצריך מבחינת קנוניקלים של Rel=prev/next.
טוב, זה אמנם לא חובה – אבל זה יכול לצמצם לכם לא מעט תוצאות אם החנות היא ענקית והקטגוריות מכילות עשרות עמודים.
ברוב אתרי החנויות – בכל עמוד קטגוריה מוצגים 10-12 מוצרים והשאר: או נטענים עם הגלילה ב Infinite scroll או ניתנים לדפדוף במערכת הPagination.
אם החנות שלכם מציגה מוצרים בקטגוריה עם Infinite Scroll – מומלץ להגדיר את הצפרדע עם ההגדרות המדריך הזה.
אם החנות שלכם עובדת עם Pagination מומלץ להגיד לצפרדע – שלא להציג תוצאות מעבר לעמוד הראשון. למה? כי לא מעניין אותנו כמה עמודים יש בקטגוריה – מעניין אותנו אם העמוד נסרק כמו שצריך – ומכיוון שכל עמודי קטגוריה בנויים אותו הדבר – מספיק לסרוק עמוד אחד. למעשה – מה שחשוב לנו זה שהקטגוריה נסרקה, גוגל מזהה את זה שיש עמודים נוספים – וכמובן שהמוצרים בקטגוריה נסרקו.
אז בצפרדע נגדיר:
Configuration -> Spider -> Basic
ונסמן Crawl next/prev – במטרה שגוגל יסרוק את כל העמודים.

ואז נבקש ממנו שלמרות שהוא סורק בפועל את העמודים – שלא יציג את העמודים האלו בתוצאות:
נעבור ללשונית Advanced – ונסמן Respect Next/Prev.

זה יסגור לנו את הפינה. ככה יסרקו כל עמודי קטגוריה – אבל בצפרדע נראה רק את העמוד הראשון. אם אנחנו רוצים לראות שהצפרדע אכן מכירה בעמודים הנוספים – נוכל לראות בלשונית Pagination – שלכל עמוד בקטגוריה רבת עמודים יש "next".
צמצום וריאציות מוצרים
כאן יש קצת דילמה – האם אנחנו רוצים שהצפרדע תציג לנו בתוצאות את כל הווריאציות האפשריות למוצר או רק את הווריאציה הראשית?
דוגמה:
יש לנו אתר בית מרקחת שמוכר מוצר אחד בגדלים שונים (למשל ויטמין C באריזה של 10 קפסולות, 40 קפסולות ו200 קפסולות) – אם מדובר באותו מוצר עם אותו התוכן כשהמשתנה היחיד הוא גודל האריזה – אנחנו נעשה בניהם קנוניקל על מנת להימנע מהכפלת תוכן.
אנחנו צריכים לשאול את עצמנו לפני הסריקה האם מעניין אותנו לסרוק את כל 3 הווריאציות (כפול כמות המוצרים שיש באתר שיש להם מספר וריאציות) או שמספיק לנו רק המוצר הראשי.
במקרה ונחליט שאנחנו רוצים לראות רק את המוצר הראשי – נבקש מהצפרדע שתכבד את הגדרות הקנוניקל – ולא תציג לנו עמודים קנונים. ההגדרה הזו היא כמובן לא רק על מוצרים – אלא על כל עמודי האתר. ולכן כדאי לחשוב אם היא נחוצה. ברוב המוחלט של המקרים – אין צורך להציג עמודים קנונים ולכן כדאי להעיף אותם:
Configuration -> Spider -> Basic
ונוודא שCrawl canonical מסומן – כך הצפרדע תבדוק האם לעמוד יש כתובת קנונית – ותסרוק אותה.

ואז נבקש מהצפרדע שתכבד את הגדרות הקנוניקל ו"תתעלם" מעמודים שיש להם קנוניקל:
נעבור ללשונית Advanced – ונסמן Respect Canoniacl.
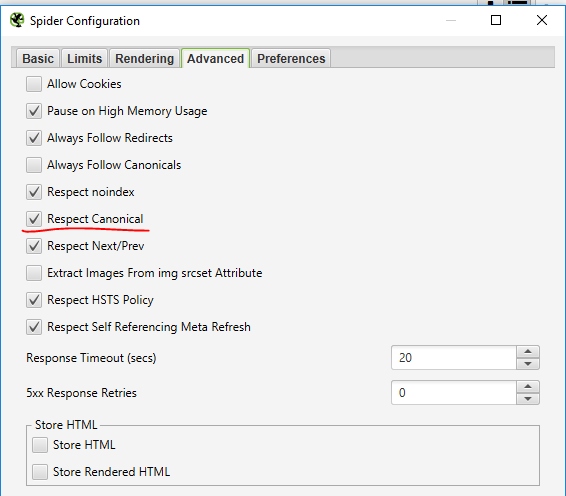
שימו לב שהפעולה הזו יעילה מאוד כשסורקים אתרים עם רינדור של JS – שסורק את כל הסקריפטים באתר שכוללים כל מני קישורים עם פרמטרים של # באג'קס ועוד ומייצרים כתובות מיותרות במערכת. אז הפעולה הזו פשוט מונעת סריקה של ערימות של שכפולי עמודים מיותרים.
זהו – העפנו עמודי מערכת מיותרים.
אבל זה לא מספיק.
חסימת קישורי הוספה לסל קניות ועוד
הצפרדע שלנו היא חיה לא מאוד חכמה. אפשר לאלף אותה – אבל היא לא עושה הסקת מסקנות לבד. מה זה אומר? זה אומר שבכל סריקת עמוד – הצפרדע סורקת ונכנסת לכל הקישורים שיש בעמוד.
בלא מעט מערכות פופולריות (למשל WooCommerce) – קישור ההוספה לסל הקניות מייצר עמוד מערכת חדש.
למשל:
נכון שלעמוד הזה ממילא יהיה קישור קנוני ל https://www.domain.co.il/product-category/brand/ אבל אין שום סיבה או רצון שהצפרדע תפתח אותו בכלל בשביל לסרוק אותו ולוודא אם יש לו קנוניקל… אנחנו רוצים לחסוך פה זמן ולצמצם משאבים – ומכיוון שמבנה הקישור הזה הוא זהה לכל אורך האתר – פשוט נעשה לביטוי הזה Exclude מהסריקה וזהו.
אז איך עושים את זה?
הולכים ל Configuration -> Exclude
ומוסיפים את הביטוי של "הוספת מוצר" במקרה של Woocommerce זה add-to-cart.
אז מוסיפים בצורה הבאה: .*\?add-to-cart.* כדי לוודא שלא תסרק אף כתובת שמכילה את הביטוי.

אם אתם לא בטוחים איך זה עובד במערכת שלכם – תסרקו עמודי מוצר או עמוד קטגוריה ותראו אם מופיעים קישורים כאלו בתוצאות – ומשם תגזרו לסריקה הכללית.
מתי עוד נשתמש בExclude?
נשתמש באופציה הזו בעיקר באתרי קוד סגור שאין בהם קנוניקלים לעמודי פילטר בקטגוריה – והם מייצרים עמוד נוסף לכל חיתוך.
במקרה הזה – נזהה מה הפרמטר שנוסף בסריקה – ונחסום אותו גם.
למשל באתרי קונימבו (שלהם יש הגדרות נוספות נדרשות) – אנחנו נרצה לסנן את הפילטרים שמסננים לפי טווחי מחירים. אז פשוט נחסום את תוספת הפרמטרים שהמערכת מוסיפה לURL (למשל mid,low,top – רק שימו לב שאלה מילים גנריות – חשוב להשתמש בזהירות ולוודא שאנחנו לא חוסמים על הדרך עמודים לגיטימיים שמכילים את הביטויים האלו)
בקיצור – מומלץ לחסוך את הסריקה של כל כתובות הפרמטרים של האתר של מיונים ופילטורים. אלו שמסדרים את הקטגוריות בסדר א"ב או מהזול ליקר וכו'. לרוב מוצאים את הפרמטרים האלו בקלות בגלישה רגילה באתר.
אז כמה חסכנו?
זו התוצאה שקיבלתי אחרי כל ההגדרות:

כלומר: חיסכון של מעל 90%(!) בסריקת האתר.
למה זה טוב?
קודם כל – חסכנו משאבים. במקרה של אתרים על שרת לא חזק במיוחד – ריצה כבדה של הצפרדע עלולה לייצר עומס ואטיות על השרתים – ולכן אם צמצמנו את הסריקה – הקלנו על המערכת.
חסכנו זמן – במקום שסריקה תיקח כמה שעות ולפעמים לילות שלמים – היא לקחה שעה וקצת.
חסכנו זמן ניתוח – הרבה יותר פשוט לנתח תוצאות מצומצמות של 2000 עמודים מאשר כמה עשרות אלפים.
לא איבדנו כלום – הנתונים שקיבלתי מכילים את כל עמודי האתר ואם יש בעיות – יש סבירות גבוהה שאני אמצא אותן בתוצאות המצומצמות.
בנוסף – אם מדובר באתר שהמערכת שלו לא מייצרת מפת אתר אוטומטית – התוצאות האלו הן הרלוונטיות ביותר ליצירת מפת אתר באמצעות הצפרדע – מפת אתר שתכיל רק את העמודים ה"אמיתיים" של האתר ולא עמודים קנונים וכו'.
סיכום
לאחר כתיבת המאמר – עברתי על התוצאות שקיבלתי ב2 הסריקות – ובדקתי 3 אתרים שונים במערכות שונות (מג'נטו, קונימבו וWooCommerce). התוצאות היו זהות כמעט לחלוטין. בכל הנוגע לקישורי 404 פנימיים, כמות קישורים יוצאים, כל מה שקשור לתגיות מטא, H1 ושאר נתונים – כל מה שמצאתי בסריקה המקיפה הענקית – מצאתי גם בסריקה המצומצמת.
בקיצור – אין שום סיבה לבזבז זמן ומשאבים.
מקווה שהזמן שהשקעתם בקיראת המאמר הוחזר לכם בייעול הזמן בסריקה.



מעולה!!
אחלה מאמר ותורם המון לבעלי חנות וירטואלית.